First tests with SQL Server vNext on Linux and Windows
The IT world is changing. The major players are changing. The old rules are evolving and the old barriers between “gardens” are disappearing. Microsoft is changing, but it is not alone. The first preview of Microsoft SQL Server vNext for Linux debuted in November 2016. On the same day, Microsoft became a platinum member of the Linux Foundation. And on the same day Google joined the .NET Foundation Technical Steering Group (Google announcement here).

SQL server vNext on Linux and Windows
I am too curious, so I immediately created a couple of VM on Azure to try the new SQL Server on Linux, Ubuntu 16.04, and on Windows Server 2016. The VMs are D2_V2 (2 core, 7 GB ram). Both virtual machines run on a standard storage account, i.e. traditional hard disks.
The setup on Linux was straightforward and fast. Starting from a running Ubuntu 16.04 and following the documentation, in less than 10 minutes I have got a running Sql Server. The installation is done through APT. Before starting, it is necessary to update the package repositories list and the a simple command installs SQL Server:
sudo apt-get install -y mssql-server
After that, another command allows choosing the SA password and setup the start-up mode of the sql service:
sudo /opt/mssql/bin/sqlservr-setup
That’s all. SQL Server is running on Linux! But bear in mind that SQL Server for Linux lacks a lot of features compared to the full version for Windows. Details here. You should also install the tools sqlcmd and bcp for Linux.

On Windows Server 2016 the installation was much longer: the iso or cab needed to be downloaded first. The well-known (old?) graphical setup wizard has many options and executes a lot of checks during the setup. It required more than 40 minutes to complete.
Connecting from a remote machine
I managed both the SQL servers directly from my PC through the internet using the SQL Management Studio (it is recommended to upgrade to the latest version. Previous version sometime hangs managing Linux machines).
To connect to the remote machines, I needed to add a security rule to allow inbound TCP traffic on port 1433 on both virtual machines. Important note: you should restrict the allowed source to your public IP. It is not a good idea to expose a sql tcp port to the full internet.
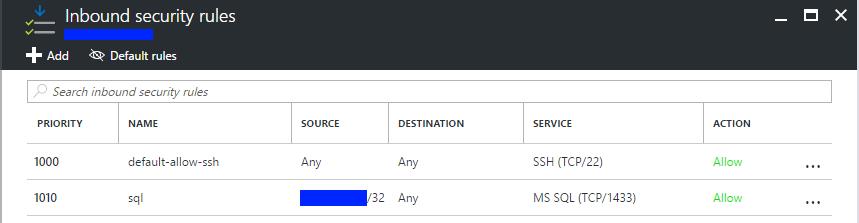
On Windows Server 2016 it is also required a similar rule on the internal firewall. On the other hand, Linux is already open to accept connections (perhaps too much open, in my opinion).
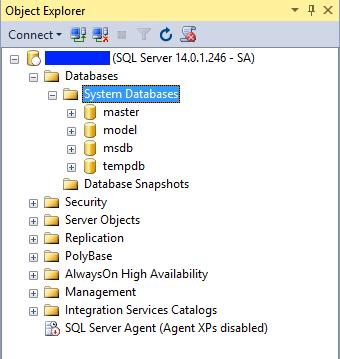
Using the latest SQL Server Management Studio, I created an empty database on both the VMs. A funny behavior: the paths from the Linux machine are always prefixed with a “C:”, so the resulting path is something like: C:\var\opt\mssql\data\mytestdb.mdf
Restore a database
I downloaded the sample AdventureWork2014 backup from Microsoft site and restored it on both VMs. The command was the same:
RESTORE DATABASE [AdventureWorks2014]
FROM DISK = N'C:\Fabry\sql_backup\AdventureWorks2014.bak'
WITH FILE = 1,
MOVE N'AdventureWorks2014_Data'
TO N'C:\Fabry\mssql_data\AdventureWorks2014_Data.mdf',
MOVE N'AdventureWorks2014_Log'
TO N'C:\Fabry\mssql_data\AdventureWorks2014_Log.ldf',
NOUNLOAD, STATS = 5
RESTORE DATABASE [AdventureWorks2014]
FROM DISK = N'C:\home/Fabry/db_backup\AdventureWorks2014.bak'
WITH FILE = 1,
MOVE N'AdventureWorks2014_Data'
TO N'C:\var\opt\mssql\data\AdventureWorks2014_Data.mdf',
MOVE N'AdventureWorks2014_Log'
TO N'C:\var\opt\mssql\data\AdventureWorks2014_Log.ldf',
NOUNLOAD, STATS = 5
Some performance tests
AdventureWorks2014 database is not so big for a D2_V2 virtual machine. So I decided to “fatten” it using the script from sqlskills.com. It creates two new big tables, Sales.SalesOrderHeaderEnlarged and Sales.SalesOrderDetailEnlarged.
The first run of the script was done without changing the predefined auto-growth of the database files. The resulting mdf was 1.5 GB and the LDF was 5 GB. A lot of time was consumed by allocating new disk space. This is the normal behavior of sql server and both the versions behaved the same way. I did a second run, after removing the two new tables. As expected it was faster.
| First run | Second run | |
|---|---|---|
| Windows | 00:10:19 | 00:03:44 |
| Linux | 00:05.06 | 00:02:31 |
Linux was faster than Windows on both cases. It is surprising. I expected SQL server on Linux slower than Windows. I repeated the tests and the result are the same.
I did other tests running different queries and Linux was always faster. I repeated the test after couple of days. The VMs were shutdown, deallocated and restarted. The results were more or less the same. I am still investigating about these strange results.
| Windows | Windows | Linux | Linux | |
|---|---|---|---|---|
| Query | Cpu time | Elapsed time | Cpu time | Elapsed time |
| (0) | 57000 | 34000 | ||
| (1) | 4329 | 2667 | 2919 | 6037 |
| (2) | 4390 | 2287 | 2344 | 1316 |
| (3) | 56092 | 38323 | 31683 | 21553 |
| (4) | 3063 | 1877 | 1713 | 862 |
(milliseconds)
Query_0
SELECT count_big(1) FROM
HumanResources.Department as T1, HumanResources.Department as T2,
HumanResources.Department as T3, HumanResources.Department as T4,
HumanResources.Department as T5, HumanResources.Department as T6,
HumanResources.Department as T7, HumanResources.Department as T8
Query_1
CHECKPOINT
DBCC DROPCLEANBUFFERS
SELECT distinct
sales.SalesOrderHeaderEnlarged.salesorderid,
Production.Product.Name
from Sales.SalesOrderHeaderEnlarged
inner join Sales.SalesOrderDetailEnlarged
on Sales.SalesOrderHeaderEnlarged.SalesOrderID =
Sales.SalesOrderDetailEnlarged.SalesOrderID
inner join Production.Product
on Production.Product.ProductID =
Sales.SalesOrderDetailEnlarged.ProductID
where linetotal > 20000
Query_2
...like Query_1 but without CHECKPOINT and DBCC DROPCLEANBUFFERS
Query_3
SELECT count(1)
FROM [Sales].[SalesOrderDetail] as SOD1,
[Sales].[SalesOrderDetail] as SOD2
WHERE SOD1.ProductID=SOD2.ProductID
AND SOD1.UnitPrice > SOD2.UnitPrice
Query_4
SELECT distinct [CarrierTrackingNumber]
FROM [Sales].[SalesOrderDetailEnlarged]
[UPDATE 2016-12-04]
Following the notes from Marco Russo, I started a larger session of tests using different machine size on Azure. The results are very contradictory and inconsistent, in particular using virtual machine of the DS series. Different runs in different time in the day, showed different results. I can only guess about the reasons (CPU overcommitment?). On the other hand, DSv2 series showed a more stable behavior. The table below shows the results.
| Windows | Linux | Linux VS Windows | |||||
|---|---|---|---|---|---|---|---|
| VM size | query | cpu time | elapsed time | cpu time | elapsed time | cpu time | elapsed time |
| D2_V2 | 0 | 61594 | 36302 | 60037 | 34298 | -2.53% | -5.52% |
| D2_V2 | 1 | 2687 | 4475 | 2448 | 3126 | -8.89% | -30.15% |
| D2_V2 | 2 | 2891 | 1827 | 2304 | 1266 | -20.30% | -30.71% |
| D2_V2 | 3 | 33531 | 23454 | 30760 | 20974 | -8.26% | -10.57% |
| D2_V2 | 4 | 1984 | 1008 | 1649 | 830 | -16.89% | -17.66% |
| D11_V2 | 0 | 63078 | 37782 | 56302 | 32051 | -10.74% | -15.17% |
| D11_V2 | 1 | 3296 | 4276 | 2532 | 3915 | -23.18% | -8.44% |
| D11_V2 | 2 | 2796 | 2135 | 2110 | 1536 | -24.54% | -28.06% |
| D11_V2 | 3 | 35234 | 24252 | 29466 | 20013 | -16.37% | -17.48% |
| D11_V2 | 4 | 1953 | 982 | 1507 | 759 | -22.84% | -22.71% |
| DS2_V2 | 0 | 57593 | 32205 | 58225 | 33492 | 1.10% | 4.00% |
| DS2_V2 | 1 | 1954 | 6339 | 2889 | 6016 | 47.85% | -5.10% |
| DS2_V2 | 2 | 2359 | 1368 | 2343 | 1340 | -0.68% | -2.05% |
| DS2_V2 | 3 | 30844 | 21008 | 30984 | 20937 | 0.45% | -0.34% |
| DS2_V2 | 4 | 1687 | 844 | 1578 | 795 | -6.46% | -5.81% |
| DS11_V2 | 0 | 57047 | 31664 | 60381 | 34344 | 5.84% | 8.46% |
| DS11_V2 | 1 | 2094 | 6325 | 2818 | 6048 | 34.57% | -4.38% |
| DS11_V2 | 2 | 2296 | 1274 | 2271 | 1242 | -1.09% | -2.51% |
| DS11_V2 | 3 | 30078 | 20419 | 31596 | 21454 | 5.05% | 5.07% |
| DS11_V2 | 4 | 1672 | 851 | 1614 | 816 | -3.47% | -4.11% |